Performance competition is a good thing
February 24, 2016 • Nate Brady
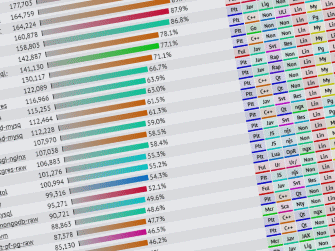
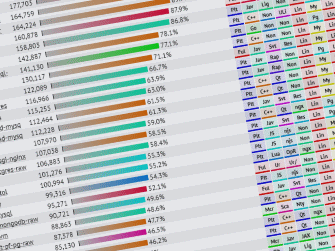
We started the Framework Benchmarks project to collect data about performance. As the project has matured, we’ve realized it has a new, perhaps even more important reason for being: encouraging both application developers and framework creators to think more about performance.