
26 languages, 431 frameworks, 1774 benchmarks; and the knock on benefits to the the users of any framework that actively participates are enormous – you are truly doing great work!
— Ben Adams (@ben_a_adams) May 24, 2018
Recent months have been a very exciting time for this project. Most importantly, the community has been contributing some amazing test implementations and demonstrating the fun and utility of some good-natured performance competition. More on that later. This is a longer-than-average TFB round announcement blog entry, but there is a lot to share, so bear with me.
Dockerification… Dockerifying… Docking?
After concluding Round 15, we took on the sizeable challenge of converting the full spectrum of ~460 test implementations from our home-brew quasi-sandboxed (only mostly sandboxed) configuration to a stupefying array of Docker containers. It took some time, but The Great Dockerification has yielded great benefits.
Most importantly, thanks to Dockerizing, the reproducibility and consistency of our measurements is considerably better than previous rounds. Combined with our continuous benchmarking, we now see much lower variability between each run of the full suite.
Across the board, our sanity checking of performance metrics has indicated Docker’s overhead is immeasurably minute. It’s lost in the noise. And in any event, whatever overhead Docker incurs is uniformly applicable as all test implementations are required to be Dockered.
Truly, what we are doing with this project is a perfect fit for Docker. Or Docker is a perfect fit for this. Whichever. The only regret is not having done this earlier (if only someone had told us about Docker!). That and not knowing what the verb form of Docker is.
Dockerificationization.
New hardware
As we mentioned in March, we have a new physical hardware environment for Round 16. Nicknamed the “Citrine” environment, it is three homogeneous Dell R440 servers, each equipped with a Xeon Gold 5120 CPU. Characterized as entry- or mid-tier servers, these are nevertheless turning out to be impressive when paired with a 10-gigabit Ethernet switch.
Being freshly minted by Dell and Cisco, this new environment is notably quicker than equipment we have used in previous rounds. We have not produced a “difference” view between Round 15 and Round 16 because there are simply too many variables—most importantly this new hardware and Docker—to make a comparison remotely relevant. But in brief, Round 16 results are higher than Round 15 by a considerable margin.
In some cases, the throughput is so high that we have a new challenge from our old friend, “network saturation.” We last were acquainted with this adversary in Round 8, in the form of a Giant Sloar, otherwise known as one-gigabit Ethernet. Now The Destructor comes to us laughing about 10-gigabit Ethernet. But we have an idea for dealing with Gozer.
(Thanks again to Server Central for the previous hardware!)
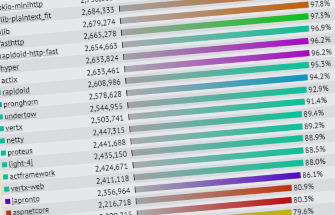
Convergence in Plaintext and JSON serialization results
In Round 16, and in the continuous benchmarking results gathered prior to finalizing the round, we observed that the results for the Plaintext and JSON serialization tests were converging on theoretical maximums for 10-gigabit networking.
Yes, that means that there are several frameworks and platforms that—when allowed to use HTTP pipelining—can completely saturate ten gigabit per second with ~140-byte response payloads using relatively cheap commodity servers.
To remove the network bottleneck for future rounds, we are concocting a plan to cross the streams, in a manner of speaking: use lasers and the fiberoptic QSFP28 ports on our Cisco switch to bump the network capacity up a notch.
The observed convergence of plaintext and JSON results from ultra high-perf implementations will likely lead to network changes beyond Round 16. See https://t.co/leqTtLK1dz pic.twitter.com/Od1nuq0UQV
— TechEmpower Framework Benchmarks (@TFBenchmarks) May 17, 2018
Expect to hear more about this as the plan develops during Round 17.
Continuous benchmarking
Introduced prior to Round 16, the continuous benchmarking platform really came into a fully-realized state in the past several months. Combined with the Great Dockening, we now see good (not perfect, but good) results materializing automatically every 67 hours or thereabouts.
Some quick points to make here:
- We don’t expect to have perfection in the results. Perfection would imply stability of code and implementations and that is not at all what we have in mind for this project. Rather, we expect and want participants to frequently improve their frameworks and contribute new implementations. We also want the ever-increasing diversity of options for web development to be represented. So expecting perfection is incongruous with tolerating and wanting dynamism.
- A full suite run takes 67 hours today. This fluctuates over time as implementation permutations are added (or deleted).
- Total execution time will also increase when we add more test types in the future. And we are still considering increasing the duration of each individual benchmarking exercise (the duration we run the load generator for to gather a single result datum). That is the fundamental unit of time for this project, so increasing that will approximately linearly increase the total execution time.
- We have already seen tremendous social adoption of the continuous benchmarking results. For selfish reasons, we want to continue creating and posting official rounds such as today’s Round 16 periodically. (Mostly so that we can use the opportunity to write a blog entry and generate hype!) We ask that you humor us and treat official rounds as the super interesting and meaningful events that they are.
- Jokes aside, the continuous results are intended for contributors to the project. The official rounds are less-frequent snapshots suitable for everyone else who may find the data interesting.
Social media presence
As hinted above, we created a Twitter account for the TechEmpower Framework Benchmarks project: @TFBenchmarks. Don’t don’t @ us.
Engaging with the community this way has been especially rewarding during Round 16 because it coincided with significant performance campaigns from framework communities.
Rust has blasted onto the server-side performance scene with several ultra high-performance options that are competing alongside C, C++, Go, Java, and C#.
#rustlang Rust now comes out on top comfortably in the TechEmpower benchmarkshttps://t.co/8PtazKQIgS
— Iwan van der Kleijn (@soyrochus) March 28, 2018
Speaking of C#, a mainstream C# framework from a scrappy startup named Microsoft has been taking huge leaps up the charts. ASP.NET Core is not your father’s ASP.NET.
And https://t.co/F00DDPy4ea core moves to the #4 slot in TechEmpower plaintext. https://t.co/x8ZCUqMpkU
— John Montgomery (@Johnmont) May 24, 2018
Warming our hearts with performance
There is no single reason we created this project over five years ago. It was a bunch of things: frustration with slow web apps; a desire to quantify the strata of high-water marks across platforms; confirming or dispelling commonly-held hunches or prevailing wisdom about performance.
But most importantly, I think, we created the project with a hopeful mindset of “perhaps we can convince some people to invest in performance for the better of all web-app developers.”
With expectations set dutifully low from the start, we continue to be floored by statements that warm our heart by directly or indirectly suggesting an impact of this project.
When asked about this project, I have often said that I believe that performance improvements are best made in platforms and frameworks because they have the potential to benefit the entire space of application developers using those platforms. I argue that if you raise the framework’s performance ceiling, application developers get the headroom—which is a type of luxury—to develop their application more freely (rapidly, brute-force, carefully, carelessly, or somewhere in between). In large part, they can defer the mental burden of worrying about performance, and in some cases can defer that concern forever. Developers on slower platforms often have so thoroughly internalized the limitations of their platform that they don’t even recognize the resulting pathologies: Slow platforms yield premature architectural complexity as the weapons of “high-scale” such as message queues, caches, job queues, worker clusters, and beyond are introduced at load levels that simply should not warrant the complexity.
So when we see developers upgrade to the latest release of their favorite platform and rejoice over a performance win, we celebrate a victory. We see a developer kicking performance worry further down the road with confidence and laughter.
Spot where I upgraded my website to #AspNetCore 2.1 yesterday: pic.twitter.com/m0rRgNL6G9
— Martin Costello (@martin_costello) June 1, 2018
I hope all of the participants in this project share in this celebration. And anyone else who cares about fast software.
On to Round 17!
Technical notes
Round 16 is composed of:
- Run 6bb9ecf9-5be0-4cb4-b52b-16ea1a3b105b from Azure.
- Run aad43f39-48a2-460c-a363-99cd543a772a from Citrine.