There are a variety of possible reasons that you could be having challenges with development. It could be the process, communication, team, or a host of related issues. We can help you assess what is going on and get things back on track.
We are often brought in by people who want to evaluate software and teams as part of a due diligence effort. This could be part of an acquisition where the acquiring party wants an opinion on the quality of the software and team. We also are brought in to evaluate the technology that is being built by a startup as part of investment due diligence.
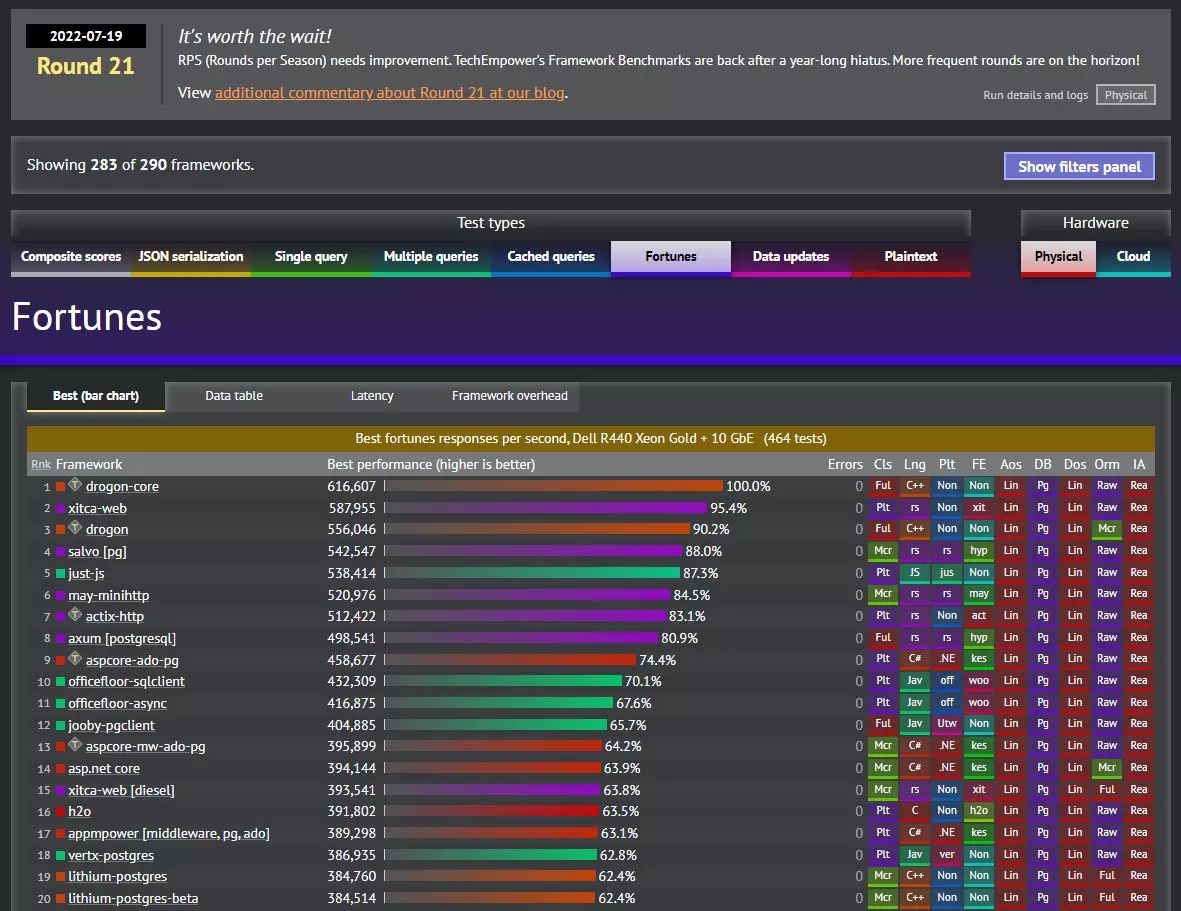
We are passionate about performance. The open source TechEmpower Web Framework Benchmarks project measures the performance of dozens of languages and application frameworks and has demonstrated that technology choices strongly influence performance results. It has been viewed hundreds of thousands of times by web application developers.
Our engineers are experts at improving the performance of applications and scaling both existing and new applications. We have worked on many systems that started with limited budgets but eventually scaled to millions of users.